-
[데이터베이스 시스템 ver.7] 챕터5데이터베이스 시스템 책 정리 2025. 4. 17. 10:01
아래 세 요소는 응용프로그램에서 DB에 접근하고 관리할 수 있게 하는 API다.
MySQL, PostgreSQL, OracleDB 등 다양한 데이터베이스와 상호 작용할 수 있는 표준 방식을 제공한다.
JDBC ODBC Python Database API java 전용 C/C++, Ruby, Go, PHP, Visual Basic 등에서 사용 python 전용
JDBC (Java Database Connectivity)
아래는 JDBC를 이용하여 "SELECT name FROM users" 쿼리를 호출하는 코드다.
Connection, PreparedStatement, ResultSet을 이용한다.
public void printUserNames() { String url = "jdbc:mysql://localhost:3306/your_database"; String user = "your_username"; String password = "your_password"; String query = "SELECT name FROM users"; try ( Connection conn = DriverManager.getConnection(url, user, password); //DB에 접속 PreparedStatement pstmt = conn.prepareStatement(query); //쿼리 실행 ResultSet rs = pstmt.executeQuery() //쿼리 결과 저장 ) { while (rs.next()) { System.out.println(rs.getString("name")); } } catch (SQLException e) { e.printStackTrace(); // 자원은 자동으로 닫힘 } }try-catch를 사용하자
sql 구문 호출 중 java에서 예외 발생시 Connection, PreparedStatement, ResultSet 같은 자원을 반납하지 않아 sql 자원 누수가 일어날 수있다. 따라서 try-with-resources 문을 사용하여 반납해주어야 한다.
try-catch보단 try-with-resources
try-with-resources는 try-catch의 특별한 형태이며, 자동 자원 정리를 포함하는 try문이다. 덕분에 예외 발생시 conn, pstmt, rs가 자동으로 close()되어 안전하게 반납된다.
준비된 구문 (동적 변경)
런타임 중에 쿼리를 동적으로 변경할 수 있다.
SQL을 미리 컴파일해서 준비해두고, 나중에 파라미터만 바꿔서 실행할 수 있는 SQL 객체다.
"?" 로 비워두고 나중에 채우는 식으로 구현한다.
SQL Injection을 효과적으로 막을 수 있다.
public void printUserNameById(int userId) { String url = "jdbc:mysql://localhost:3306/your_database"; String user = "your_username"; String password = "your_password"; String query = "SELECT name FROM users WHERE id = ?"; // 준비된 구문 try ( Connection conn = DriverManager.getConnection(url, user, password); PreparedStatement pstmt = conn.prepareStatement(query) ) { pstmt.setInt(1, userId); // 첫 번째 ?에 userId 바인딩 try (ResultSet rs = pstmt.executeQuery()) { while (rs.next()) { System.out.println(rs.getString("name")); } } } catch (SQLException e) { e.printStackTrace(); } }
SQL injection (sql 공격)
준비된 구문을 이용하여 악의적으로 "?"에 쿼리문을 작성하여 예상치 못한 쿼리문을 날리는 공격 방법이다.
이는 QueryDSL, JPA 등을 사용하여 사용자가 쿼리를 직접적으로 작성하지 못하도록 방지할 수 있다.
CallableStatement (프로시저 or 함수 호출시)
일반 SQL문을 호출하는 PrepareStatement와 다르게 CallableStatement는 DB에 저장된 프로시저나 함수를 호출할때 사용한다.
아래와 같은 저장 프로시저 get_user_name 이 있다고 가정할때,
CREATE PROCEDURE get_user_name(IN user_id INT, OUT user_name VARCHAR(100)) BEGIN SELECT name INTO user_name FROM users WHERE id = user_id; END;get_user_name을 호출하는 JDBC 코드는 아래와 같다.
public void printUserNameById(int userId) { String url = "jdbc:mysql://localhost:3306/your_database"; String user = "your_username"; String password = "your_password"; String procedureCall = "{call get_user_name(?, ?)}"; // 저장 프로시저 호출 try ( Connection conn = DriverManager.getConnection(url, user, password); CallableStatement cs = conn.prepareCall(procedureCall) ) { cs.setInt(1, userId); // IN 파라미터 cs.registerOutParameter(2, Types.VARCHAR); // OUT 파라미터 cs.execute(); // 프로시저 실행 String name = cs.getString(2); // OUT 파라미터 값 얻기 System.out.println("User Name: " + name); } catch (SQLException e) { e.printStackTrace(); } }DB 컬럼명과 java 필드명은 따로 사용하자
JDBC 작성시 DB 컬럼명을 직접 작성하면 컬럼명이 변경되는 경우 모두 수정해야 한다.
아래 예시의 경우 "name" 으로 하드코딩되어있는데, "pk_name"으로 변경되면 이를 손수 모두 변경해주어야 한다.
// 안좋은 예 while (rs.next()) { System.out.println(rs.getString("name")); // "name"이라는 컬럼명 고정 }따라서 런타임중에 DB에서 컬럼명을 읽어오자.
// 좋은 예 ResultSetMetaData rsmd = rs.getMetaData(); int colCount = rsmd.getColumnCount(); while (rs.next()) { for (int i = 1; i <= colCount; i++) { System.out.println(rs.getString(i)); // 컬럼 순서로 접근 } }mybatis와 jpa에도 이 기능을 지원한다.
대신 JDBC와 다르게 java 필드명을 생성하여 따로 사용하는 방식이다.
DB 컬럼명은 "name"이고, java 필드명은 "userName"으로 정한다 가정하자.
mybatis 사용시 아래와 같고,
<resultMap id="userMap" type="User"> <result property="userName" column="name"/> </resultMap>jpa 사용시 아래와 같다.
@Entity public class User { @Column(name = "name") // DB 컬럼명 private String userName; // 자바 필드명 }정리: JDBC의 기능
- java로 쿼리 호출 (정적쿼리, 동적쿼리, 함수, 프로시저)
- java로 DB에서 메타데이터 읽어오기
- commit, rollback
단, java에서 오류 발생시 쿼리 자원을 반환해야 한다
procedures, functions
이미지나 도형 같은 특수 데이터 타입 처리에 유용
ex) 지도 db에서 두 선분이 겹치는지 검사하는 함수, 두 이미지의 유사성을 비교하는 함수
아래는 테이블을 반환하는 함수다. 이는 매개변수를 받는 뷰와 같다
CREATE FUNCTION instructor_of (dept_name varchar(20)) RETURNS TABLE ( --반환 타입 정의 id VARCHAR(5), name VARCHAR (20), dept_name VARCHAR (20), salary NUMERIC (8,2)) RETURN TABLE --반환 값 (SELECT id, name, dept_name, salary FROM instructor WHERE instructor dept_name = instructor_of_dept_name);위 함수는 아래처럼 쓰인다
SELECT * FROM TABLE (instructor_of("Finance"))아래는 프로시저다.
IN과 OUT을 이용해 입력값과 반환값을 구분한다.
CREATE PROCEDURE dept_count_proc(IN dept_name CARCHAR(20), OUT d_count INTEGER) --IN,OUT 사용 BEGIN SELECT COUNT(*) INTO d_count --d_count에 결과값 넣기 FROM instructor WHERE instructor dept_name=dept_count_proc.dept_nanme END위 프로시저는 아래처럼 쓰인다
DECLARE d_count INTEGER; CALL dept_count_proc('Physics', d_count); --CALL 사용프로시저,함수에서 변수선언/정의, { }묶음 처리, while, for, if문, 예외처리 등을 지원한다.
DB마다 문법차이가 있으므로 그에 맞게 작성해야 한다.
Sandbox
개발자 측의 코드가 DB 시스템을 해치지 않도록 막는 보안 장치다.
개발자가 작성한 Java코드가 DB 내부에서 실행될 때 시스템 메모리나 파일 시스템에 임의로 접근하거나 변경하지 못하게 막는다.
Trigger
무결성 제약을 구현하거나, 특정 조건이 발생했을때 자동으로 작업하게 할 수 있는 기능이다.
ex) 데이터가 변경될 때마다 변경 내용을 별도의 로그 테이블에 저장하기
하지만 트리거는 데이터베이스 내부에서 실행되기 때문에, 전체 로직이 분산돼 보여서 코드 흐름을 이해하기 어려워진다.
아래는 트리거 문법이다.
UPDATE, INSERT, DELETE 실행 이전, 이후 모두 트리거를 설정할 수 있다
실행 이전과 이후는 BEFORE와 AFTER 키워드로 명시한다
또한 OLD와 NEW라는 키워드를 제공한다. 이는 트리거가 실행될 때 바뀌는 데이터를 참조한다.
--NEW 키워드 사용한 경우 -- INSERT 이후 id값이 잘 저장되었는지 확인하는 쿼리 CREATE TRIGGER timeslot_check AFTER INSERT ON section --AFTER 사용 FOR EACH ROW WHEN (NEW.id NOT IN ( SELECT id FROM time_slot )) BEGIN ROLLBACK END; --OLD 키워드 사용한 경우 --DELETE 이전 주키 외래키 제약조건을 만족하는 상태인지 확인하는 쿼리 CREATE TRIGGER timeslot_check BEFORE DELETE ON section --BEFORE 사용 FOR EACH ROW WHEN (OLD.id IN ( SELECT id FROM time_slot) AND OLD.id IN ( SELECT id FROM section) ) BEGIN ROLLBACK END;문법은 DBMS마다 다르니 주의하자.
재귀 쿼리
그래프 탐색 알고리즘 구현에 쓰인다.
아래는 간단한 재귀쿼리 예시다.
초기 테이블에 튜플을 무한 UNION하는 식으로 진행된다.
WITH RECURSIVE counter(n) AS ( SELECT 1 -- 초기 테이블 UNION ALL SELECT n + 1 -- 반복 규칙 FROM counter WHERE n < 5 -- 반복 조건 ) SELECT * FROM counter;UNION 아래 쿼리부분을 무한반복하고, 각 결과를 기존 테이블에 UNION한다.
반복하다가 WHERE절 조건을 만족하지 않으면 종료된다.
실제 테이블 변화 과정은 아래와 같다.





실행 결과 테이블에 1,2,3,4,5 가 삽입된다.
아래는 특정 과목 course_id의 모든 선수과목 prereq_id를 찾는 재귀쿼리 예시다.
WITH RECURSIVE rec_prereq(course_id, prereq_id) AS ( SELECT course_id, prereq_id FROM prereq WHERE course_id = 'CS-347' UNION -- 재귀 조건: 이전 결과의 선수 과목의 선수 과목을 찾음 SELECT rec_prereq.course_id, prereq.prereq_id FROM rec_prereq, prereq where rec_prereq.prereq_id = prereq.course_id ) SELECT * FROM rec_prereq;초기 테이블이 이와 같다면,

실행 결과는 다음과 같다.

순위, 집계 관련
- RANK() : 동점일 땐 같은 순위 주고, 다음 순위는 건너뜀. (1,1,3 ...)
- DENSE_RANK() : 순위를 건너뛰지 않음 (1,1,2,...).
- ROW_NUMBER() : 무조건 고유 번호 부여 (동점도 다르게)
- NTILE(n) : n개의 그룹으로 나눔, 성적 등급 부여하기에 좋음 (ex 상위 10%)
- PERCENT_RANK() : 백분율 순위 (ex (rank-1)/(n-1)),
CUME_DIST() : 누적 비율 (자신 이하의 비율). - PARTITION BY : 그룹별 순위 부여 (ex 학과별 순위)
- NULLS FIRST / LAST : null 정렬 위치 지정(**MySQL은 지원x)
- 서브쿼리에 RANK <= n : 상위 n위 학생 추출.(동점 포함 주의)
예제1
"GPA가 상위 3위에 속하는 튜플을 출력하라"

rank()를 사용하여 rank 속성 추가
-- GPA가 상위 3위에 속하는 튜플을 출력하라 SELECT * FROM ( select ID, GPA RANK() OVER (ORDER BY GPA DESC) AS rank FROM S ) ranked WHERE rank <= 3;출력 결과

예제2
"dpartment 별로 score 순위를 매겨 출력하라"

partition by 사용하여 그룹별 rank 속성 추가
SELECT name, department, score, RANK() OVER (PARTITION BY department ORDER BY score DESC) AS dept_rank FROM students;결과

Pivot
pivot은 행 데이터를 열로 바꿔서 보여주는 기능이다.
주로 카테고리별로 값을 비교하거나 요약할때 사용한다.
ex)
- 월별 제품 매출 비교
- 지역별 사용자 수 요약
- 연령대별 선호도 분석
- 옷 색상 별 판매량 비교
예를 들어, 아래와 같은 테이블이 있을때

pivot 하면 아래와 같이 변한다.

GROUP BY ROLLUP
ROLLUP은 GROUP BY의 확장으로, 누적 집계와 전체 집계를 한 번에 구할 수 있다.
예제1) GROUP BY ROLLUP(a)
아래와 같은 테이블이 있을때

아래의 쿼리를 출력하면
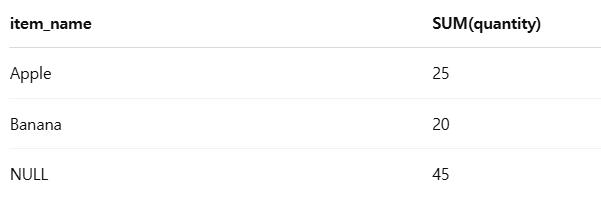
SELECT item_name, SUM(quantity) FROM sales GROUP BY ROLLUP(item_name);해당 결과가 출력된다.
예제2) GROUP BY ROLLUP(a,b)
단순 GROUP BY한 테이블이 아래와 같을때,

아래의 쿼리를 출력하면,
SELECT item_name, color, SUM(total_quantity) AS total_quantity FROM sales GROUP BY ROLLUP(item_name, color);해당 결과가 출력된다.

item_name 기준 color별 집계 튜플 먼저 나온 후 item_name별 집계 튜플 나오고, 맨 아래에 총 집계 튜플이 나온다.
주의) color 기준 item_name 별 집계는 나오지 않는다. GROUP BY ROLLUP(collor, item_name)으로 변경해야 출력된다.
GROUP BY CUBE
CUBE는 ROLLUP보다 더 일반적인 집계로, 모든 속성 조합의 그룹별 합계를 계산한다.
GROUP BY CUBE 사용한 결과 테이블이다.
ROLLUP 결과와 달리 color 기준 item_name 별 집계까지 포함해서 출력되었다.

구현 코드다.
SELECT item_name, color, SUM(quantity) AS total_quantity FROM sales GROUP BY CUBE(item_name, color);
문제풀이
5.1
ename="dog"인 mgr의 mname을 출력하고,
그 mname에서 ename=mname인 mgr이 있으면 mname을 출력하고,
그 mname에서 ename=mname인 mgr이 있으면 mname을 출력하고,
ename=mname이 없을때까지 무한 반복한다.
즉, "dog"의 매니저, 그 매니저의 매니저, 그 매니저의 매니저 .. 최상위 매니저까지 출력한다.
5.2
column_list = result.getMetaData(); for (int i=1; i<= metadata.getColumnCount(); i++){ System.out.print(metadata.getColumnName(i) + '\t'); } System.out.println(); while (result.next()){ for (int i = 1; i <= metadata.getColumnCount(); i++){ System.out.print(result.getString(i) + '\t'); } }5.3
public List<String> findAllPrereqs(String cid) { try( Connecion con = DriverManager.getConnection("jdbc:~"); PreparedStatement stmt = con.prepareStatement(); ){ String q = "select prereq_id from prereq where course_id = ?"; boolean more; ResultSet result; List<String> allPrereqs = new ArrayList<>(); do { stmt.setString(1, cid); result = stmt.executeQuery(q); more = result.next(); if (more) { cid = result.getString("prereq"); if (allPrereqs.contains(cid)){ break; //사이클 방지 } else { allPrereqs.add(cid); } } } while (more); s.close(); son.close(); return allPrereqs; } catch(Exception e){ e.printStackTrace(); } }5.4
5.5
트리거 문제
교수는 한 학기에 같은 시간 슬롯에 다른 두 개의 교실에서 가르칠 수 없다
create trigger teaches_check after insert on teaches referencing new row as nrow for each row when ( 2 <= ( select count(*) from section s, teaches t where nrow.ID = ID and nrow.semester = semester and nrow.year = year and nrow.building = building and nrow.room_number = room_number and nrow.time_slot_id = time_slot_id ) begin rollback end; )5.6
트리거 문제
create trigger update_depositor after insert on depositor referencing new row as nrow for each row begin insert into branch_cust as select branch_name, nrow.customer_name from account a where nrow.account_number=a.account_number end; create trigger update_account after insert on account referencing new row as nrow for each row begin insert into branch_cust as select nrow.branch_name, customer_name from depositor d where d.account_number=nrow.account_number end;5.7
트리거 문제
create trigger delete_after_account after delete on account referencing old row as orow for each row when ( not exists ( select * from account a left join depositor d on a.account_number=d.account_number where orow.account_number=d.account_number)) begin delete from depositor where orow.account_number=account_number end;5.8
순위화 문제
select * from ( select student, subject, marks, rank() over (order by mark DESC) as rank from S ) ranked where rank <= 10;5.9
순위화 문제
select year, month, day, shares_traded rank() ober (order by shares_traded DESC) as rank from nyse5.10
group by rollup 문제
select year, month, day, sum(shares_traded), sum(dollar_volume) from nyse group by rollup (year, month, day)5.11
grouping sets를 이용하여 모든 집합을 포함시킨다
SELECT a, b, c, d, SUM(value) FROM sales GROUP BY GROUPING SETS ( ROLLUP(a, b, c, d), ROLLUP(a, b, c), ROLLUP(a, b, d), ROLLUP(a, c, d), ROLLUP(b, c, d), ROLLUP(a, b), ROLLUP(a, c), ROLLUP(a, d), ROLLUP(b, c), ROLLUP(b, d), ROLLUP(c, d), ROLLUP(a), ROLLUP(b), ROLLUP(c), ROLLUP(d), ROLLUP() );'데이터베이스 시스템 책 정리' 카테고리의 다른 글
[데이터베이스 시스템 ver.7] 챕터4 (1) 2025.04.03 [데이터베이스 시스템 ver.7] 챕터3 (1) 2025.03.27 [데이터베이스 시스템 ver.7] 챕터1 (1) 2025.03.20 [데이터베이스 시스템 ver.7] 챕터2 (1) 2025.03.20