-
[데이터베이스 시스템 ver.7] 챕터2데이터베이스 시스템 책 정리 2025. 3. 20. 10:00
용어정리

- table (=relation)
- tuple (=row=행)
- attribute (=column=속성=열)
- instance (=value=실제값)
- domain : 어떤 attribute가 가질 수 있는 모든 값들의 집합을 정의한 것 ex) "위 그림의 attribute인 commission의 domain은 실수값이다"
- atomic domain (원자적 도메인)
한 attribute 당 하나의 instance값만 가지는 경우를 말한다.
이런 경우 데이터 수정,삭제가 용이하고, WHERE문이나 JOIN문이
atomic하지 않으면 문자열 처리를 해야 해서 연산이 비효율적이고 인덱스를 사용할 수 없어 처리 속도가 느려진다
# 비 원자적 도메인의 경우 고객 테이블 +--------+------------------+ | 고객ID | 전화번호 | +--------+------------------+ | 101 | 010-1234-5678, 02-987-6543 | | 102 | 010-4321-8765 | +--------+------------------+ # 원자적 도메인의 경우 고객 테이블 +--------+--------------+ | 고객ID | 전화번호 | +--------+--------------+ | 101 | 010-1234-5678 | | 101 | 02-987-6543 | | 102 | 010-4321-8765 | +--------+--------------+- relation schema
한 테이블명, 속성명, 도메인을 정의한 것, 즉 설계도다. 각 속성의 데이터타입, 제약 조건까지 포함한다
1. relation schema 예시 Employees( emp_id, name, department ) 2. 실제 DB에서의 relation schema 예시 CREATE TABLE Employees ( emp_id INT PRIMARY KEY, name VARCHAR(50) NOT NULL, department VARCHAR(30), );- database schema
relation schema들 + 그들의 관계 + 뷰, 인덱스 등을 모두 포괄하는 개념
- 키 종류
- superkey : tuple을 유일하게 구분할 수 있게 해주는 하나 이상의 attribute
- candidate key (후보키) : superkey 중 최소성을 만족하는 하나 이상의 키, NULL 값 허용o
- primary key : 후보키 중 NULL값이 없는 키. 하나만 존재할 수 있음
* superkey, candidate key, primary key 구분해보기

테이블 A superkey : {emp_id}, {name, department}, {emp_id, age}, {emp_id, department}, {emp_id, salary}, {emp_id, name, age} {emp_id, name, age, department}, {emp_id, name, age, department, salary} 등 (고유식별 가능한 emp_id를 포함하는 모든 집합 다 가능)
candidate key : {emp_id}
primary key : {emp_id}
- foreign key, referencing relation, referenced relation 간 구분

이 두 테이블에서 설명하면, 주문테이블의 foreign key(외래키)는 customer_id이다. 주문테이블은 referencing relation(참조하는 릴레이션)이고 고객테이블은 referenced relation(참조된 릴레이션)이다.
- referential integrity constraints (참조 무결성 제약조건) : 외래키값이 참조되는 릴레이션의 주키값 중 적어도 하나의 튜플에 있어야 한다. 즉, 부모 테이블에 존재하지 않는 주키 값을 자식 테이블의 외래키값에 삽입할 수 없다.
- foreign key Constraints (외래키 제약조건) : 참조 무결성 제약조건을 달성하기 위해 외래키 필드가 다른 테이블의 주키 필드를 참조하도록 강제하는 제약조건이다,
- SQL문에서의 외래키 제약조건
SQL에서는 아래와 같은 방식으로 무결성 제약조건 위반이 생기더라도 특정 행위를 통해 외래키 제약조건을 만족시킨다.
ON DELETE CASCADE : 특정 주키를 가진 튜플이 삭제되면 외래키 튜플도 같이 삭제해라
ON DELETE SET NULL : 특정 주키를 가진 튜플이 삭제되면 외래키 튜플을 null로 변경해라
- schema diagram (스키마 다이어그램)
주키와 외래키 종속성을 그림으로 나타낸 것

- 관계 대수
한 개 혹은 두 개의 릴레이션으로 새로운 릴레이션을 생성하는 연산들의 집합
- 관계 대수 연산
- σ(Selection) (선택)

"instructor 릴레이션에서 dept_name속성값이 "Physics"인 동시에 salary속성값이 90000을 넘는 튜플을 출력해라" - π(Projection) (추출)

"instructor 릴레이션에서 튜플의 ID, name, salary 속성값들만 출력해라" - ∪(Union) (합집합)
- - (Difference) (차집합)
r-s : "릴레이션 r에는 속하나 s에는 속하지 않는 튜플을 출력해라"
- ∩ (Intersection) (교집합)
- x (Cartesian Product) (카테시안 곱)과 ⨝ (Join)

카테시안 곱 사용한 이 관계대수는 아래 관계대수와 동치다. 
"instructor 릴레이션과 teaches 릴레이션을 join해라" - ρ (Rename)
기존 테이블의 속성명을 바꿀때 사용한다
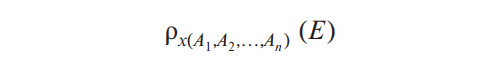
E릴레이션의 속성을A1~An라는 이름으로 바꾼다 
위와 같이 instructor 릴레이션을 참조할때 i라는 이름을 사용한다 - division (나눗셈 연산)
A ÷ B (A 나누기 B)는 A 테이블의 데이터 중에서 B 테이블에 있는 "모든" 값을 포함하는 항목들만 추출하는 연산
ex) "누가 모든 조건을 충족하는가?" 쿼리에 사용됨
SQL에는 ÷ 연산이 없으므로 **집합 연산(SUBQUERY + GROUP BY + HAVING)**을 사용해야 한다
SELECT A.Student FROM A GROUP BY A.Student HAVING COUNT(DISTINCT A.Course) = (SELECT COUNT(*) FROM B);
연습문제
2.1 그림 2.17의 관계형 데이터베이스를 생각해보자. 어떤 속성이 주 키로 가장 적합할 것인가?

-> employee은 person_name, works는 person_name, company는 company_name이다.
2.2 instructor 릴레이션의 dept_name 속성으로부터 department 릴레이션으로의 외래 키를 생각해보자. 이러한 릴레이션에서 외래 키 조건을 위반하게 되는 삽입과 삭제의 예를 들어보라.
->
삽입의 경우 : department 릴레이션(참조된 릴레이션)에 dept_name="Math"인 튜플을 삽입한다고 가정한다. department 릴레이션의 외래키 값이 삽입되었지만 instructor 릴레이션(참조하는 릴레이션)에는 존재하지 않으므로 참조 무결성 제약조건을 위반한다. 즉 외래키값의 도메인과 주키값의 도메인이 일치하지 않아 일관성이 깨진다.
(반대로 instructor 릴레이션(참조하는 릴레이션)에서 튜플을 삽입하는 경우는 참조 무결성 제약조건에 위반되지 않는다.)
삭제의 경우 : department 릴레이션(참조된 릴레이션)에서 dept_name=Biology인 튜플을 삭제한다고 가정한다. 이 경우 instructor 릴레이션(참조하는 릴레이션)에 있는 외래키 dept_name=Biology가 주키를 참조하지 못한다. 따라서 참조 무결성 제약조건을 위반한다. 즉 외래키값의 도메인과 주키값의 도메인이 일치하지 않아 일관성이 깨진다.
(반대로 instructor 릴레이션(참조하는 릴레이션)에서 튜플을 삭제하는 경우는 참조 무결성 제약조건에 위반되지 않는다.)
2.3 time_slot 릴레이션을 생각해보자. 일주일에 한 번 이상 일어나는 특정 시간이 주어졌을 때, 이 릴레이션에서 day와 start_time은 주 키의 일부분이 될 수 있지만 end_time은 주 키의 일부분이 될 수 없는 이유를 설명하라
-> 하루에 수업이 여러번 있는 경우 두 수업의 시작 시간은 다르지만 끝나는 시간은 같을 수 있기 때문이다.
하지만 두 수업의 시작시간도 같을 수 있지 않을까..
2.4 그림 2.1에 나타나 있는 instructor 인스턴스에는 같은 이름을 가진 교수가 존재하지 않는다. 이러한 사실로부터 name이 instructor의 수퍼 키 혹은 주 키가 될 수 있다고 말할 수 있는가?
-> 지금은 없더라도 나중에 같은 이름을 가진 교수가 존재할 수 있으므로 name만으로는 수퍼키, 주키가 될 수 없다.
2.5 student 릴레이션과 advisor 릴레이션의 크로스곱(cross product)을 수행하고 그 결과에 s_id=ID 조건을 만족하는 튜플을 선택하는 연산을 진행하면, 그 결과는 무엇이 되겠는가? (관계 대수의 형태로 표현하면 이 질의는 σ s_id=ID(student x advisor)가 될것이다.)
->
결과에 출력되는 튜플의 속성은 ID, name, dept_name, tot_cred, s_id, i_id이며
student의 ID와 instructor의 ID가 같은 튜플만 출력된다
한 학생이 두 명의 지도교수를 가진 경우 ID가 같은 두개의 튜플이 출력된다
지도교수가 없는 학생은 출력되지 않는다
2.6 그림 2.17의 관계형 데이터베이스를 생각해보자. 다음의 질의를 표현할 수 있는 관계대수를 제시하여라
a. "Miami"에 살고 있는 모든 직원의 이름을 출력하라.
-> π person_name(σ city="Miami"(employee))
b 급여가 $100,000가 넘는 모든 직원의 이름을 출력하라.
-> π person_name( σ salary>100000(works))
답 : Πpersonname(σsalary>100000(employee⋈works))
c. "Miami"에 살고 있으면서 급여가 $100,000이 넘는 모든 직원의 이름을 출력하라.
-> π person_name(σ city="Miami"(employee) ∧ σ salary>100000(works))
답 : Πpersonname(σsalary>100000∧city="Miami"(employee⋈works))
2.7 그림 2.18의 은행 데이터베이스를 생각해보자. 다음의 질의를 표현할 수 있는 관계대수를 제시하라.

a. "Chicago"에 위치하고 있는 모든 지점의 이름을 출력하라.
-> π branch_name(σ branch_city="Chicago"(branch))
b. "Downtown" 지점에서 대출을 한 모든 대출자의 이름을 출력하라.
-> π customer_name( π ID,customer_name(customer) ⨝ π loan_number(σ branch_name="Downtown"(loan)))
2.8 그림 2.17의 직원 데이터베이스를 생각해보자. 다음의 질의를 표현할 수 있는 관계 대수를 제시하라.
a. "BigBank"에서 일하지 않는 직원의 ID와 이름을 출력하라
π ID,person_name( employee ⨝employee.person_name=works.person_name (works - σ company_name="BigBank"(works)))
b. 적어도 데이터베이스에 있는 모든 직원만큼 급여를 받는 직원의 ID와 이름을 출력하라.
2.9 관계대수의 나누기 연산, ÷은 다음과 같이 정의된다. r(R)과 s(S)가 릴레이션이고, S⊆R이라고 하자. 즉 스키마 S의 모든 속성은 스키마 R에도 속하게 된다. 그러면 r÷s는 R - S 스키마상(즉 스키마 S에는 속하지 않는 스키마 R의 모든 속성을 포함하는 스키마상)의 릴레이션이 된다. 튜플 t가 r÷s라는 것과 다음 두 조건을 만족하는 것은 필요충분조건이다.
- t는 π R-S (r)에 속한다
- s에 속하는 모든 튜플 ts에 대해, r에 속하는 튜플 tr은 다음의 조건을 모두 만족한다.
a. tr[S] = ts[S]
b tr[R-S] = t
이상의 정의에 대해,
a. 나누기 연산을 이용하여 모든 Comp. Sci. 수업을 듣는 모든 학생의 ID를 찾는 관계 대수식을 기술하라. (힌트: 나누기 연산을 하기 전에 takes를 ID와 course_id로 추출하고, Comp. Sci의 course_id를 선택 표현식을 이용하여 생성하라)
->
b. 나누기 연산을 이용하지 않고 위 질의를 관계 대수로 어떻게 표현할 수 있는지 보여라(나누기 연산을 다른 관계 대수 연산으로 어떻게 정의했는지를 보여야 한다.)
2.10 릴레이션과 릴레이션 스키마의 차이를 설명하라
-> 릴레이션 스키마는 속성과 도메인을 정의한 것, 즉 설계도이며 릴레이션은 릴레이션 스키마를 기반으로 실제 값을 저장한 것이다.
2.11 그림 2.9의 advisor 릴레이션을 생각해보자. advisor 릴레이션의 주 키는 s_id이다. 한 명의 학생이 한 명 이상의 지도교수를 가질 수 있다고 할 때, 여전히 s_id가 advisor 릴레이션의 주 키가 될 수 있겠는가? 그렇지 않다면 advisor의 주 키로는 어떤 것이 되어야 할 것인가?
->
아래와 같이 1번 학생이 100,101 교수를 가질때, s_id는 유일성을 만족하지 못한다. 따라서 주 키가 될 수 없다.
대신 임의의 키를 따로 사용해야 한다. 튜플 삽입할때마다 1씩 증가하는 값을 대입하면 유일성을 만족할 수 있다
s_id i_id 1 100 1 101 2 102 2.12 그림 2.18의 은행 데이터베이스를 생각해보자. 지점 이름과 고객 이름은 유일하지만 한 고객은 여러 대출과 계좌를 가질 수 있다고 가정하자.
a. 주 키로는 어떤 것이 적절하겠는가?
-> customer의 ID, loan의 loan_number, account의 account_number, branch의 branch_name
b. 위에서 답한 주 키에 대한 적절한 외래키는 어떤 것이 되겠는가?
->
customer의 ID의 외래키는 borrower의 ID, depositor의 ID
loan의 loan_number의 외래키는 borrower의 loan_number
account의 account_number의 외래키는 depositor의 account_number
branch의 branch_name의 외래키는 loan의 branch_name, account의 branch_name
2.13 그림 2.18의 은행 데이터베이스를 위한 스키마 다이어그램을 구성하라

출처: https://github.com/noahabe/database_system_concepts_answers/blob/main/Ch02_Introduction_to_the_Relational_Model/2.13.md 2.14 그림 2.17의 직원 데이터베이스를 생각해보자. 다음의 질의를 표현할 수 있는 관계 대수를 제시하라
a. "BigBank"에서 일하는 모든 직원의 이름을 출력하라
π person_name(σ company_name="BigBank"(works))
b. "BigBank"에서 일하는 모든 직원의 ID, 이름과 거주하는 도시를 출력하라
π ID,person_name,city(σ company_name="BigBank"(works) ⨝ employee.person_name=works.person_name employee)
c. "BigBank"에서 일하고 $10,000 이상의 급여를 받는 모든 직원의 ID, 이름, 주소, 거주하는 도시를 출력하라
π ID,person_name,street,city(σ company_name="BigBank" ∧ salary>=10000(works) ⨝ employee.person_name=works.person_name employee)
2.15 그림의 2.18의 은행 데이터베이스를 생각해보자. 다음의 질의를 표현할 수 있는 관계 대수를 제시하라.
a. 대출 금액(amount)이 $10,000가 넘는 모든 대출(loan)의 대출 번호(loan_number)를 출력하라.
-> π loan_number(σ amount>10000(loan))
b. 예금의 잔고(balance)가 $6,000가 넘는 예금 계좌(account)를 가지고 있는 모든 예금자(depositor)의 ID를 출력하라.
-> π ID(depositor ⨝ depositor.account_number=account.account_number(σ balance>6000(account)))
c. "Uptown" 지점의 예금의 잔고(balance)가 $6,000가 넘는 예금 계좌(account)를 가지고 있는 모든 예금자의 이름(customer_name)을 출력하라.
->
2.16 데이터베이스에 널값을 도입하는 이유를 두가지 제시하라.
->
1. 튜플값을 삽입할때 특정 attribute값이 없는 경우가 있는데 그때 널값을 사용한다
2. 널값 대신 0이나 임의의 값을 사용할 수 있지만, 이로 인해 수학적 연산에서 잘못된 결과를 낼 수 있기 때문이다.
2.18 대학 스키마를 사용하여 아래의 질의에 대응하는 관계 대수를 제시하라
a. 물리학과의 모든 교수의 ID와 이름을 출력하라
b. "Watson" 빌딩에 위치한 학과에 있는 모든 교수의 ID와 이름을 출력하라
c. "Comp Sci."학과에 개설한 과목 중에서 적어도 하나의 과목을 수강하는 모든 학생의 ID와 이름을 출력하라
d. 2018년에 적어도 하나의 과목을 수강한 모든 학생의 ID와 이름을 출력하라
e. 2018년에 어떤 과목도 수강하지 않은 학생의 ID와 이름을 출력하라
'데이터베이스 시스템 책 정리' 카테고리의 다른 글
[데이터베이스 시스템 ver.7] 챕터5 (0) 2025.04.17 [데이터베이스 시스템 ver.7] 챕터4 (1) 2025.04.03 [데이터베이스 시스템 ver.7] 챕터3 (1) 2025.03.27 [데이터베이스 시스템 ver.7] 챕터1 (1) 2025.03.20